Quick Facts
- Category: Data Science
- Published: 2026-05-03 20:20:11
- GitHub Copilot Overhauls Individual Plans: New Sign-Ups Halted, Usage Caps Tightened, and Model Access Revised
- NVIDIA GPUs Vulnerable to New Rowhammer Attacks: Full System Takeover Possible
- Kazakhstan Doubles Down on Coursera Partnership to Bring For-Credit AI and Digital Skills to 235,000+ Students
- Instagram’s Failed Encryption Promise: What Happened and Why It Matters
- A School's Guide to Supporting LGBTQ+ Youth Mental Health
AI Agents Gain a Map: Meta's Pre-Compute Engine Cuts Errors by 40%
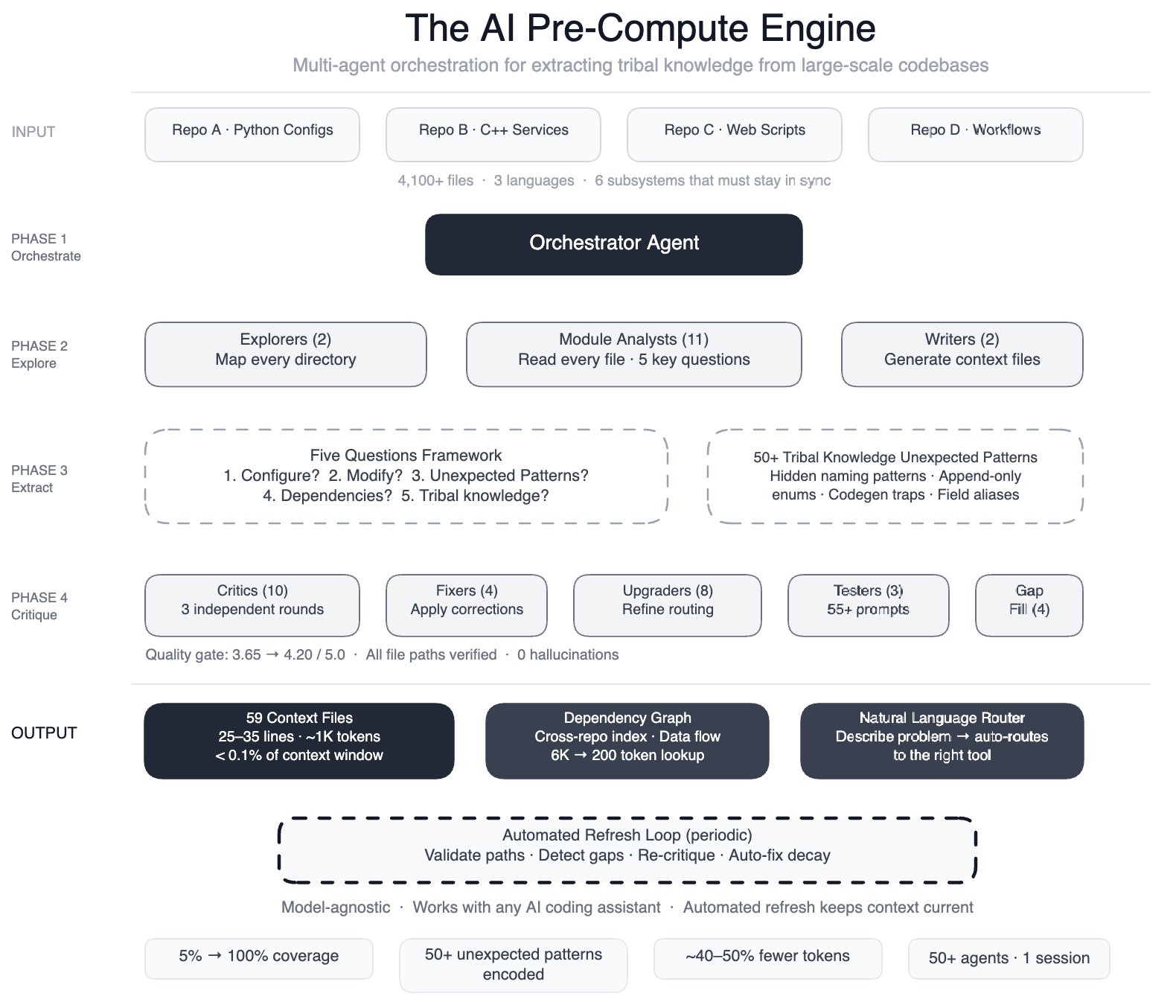
MENLO PARK, CA – Meta has revealed a breakthrough in AI-assisted coding: a swarm of 50+ specialized AI agents that systematically read every file in a massive data processing pipeline and produced 59 concise context files encoding previously undocumented tribal knowledge.

The result, according to the company, is a dramatic improvement in AI agent performance. "Our agents now have structured navigation guides for 100% of our code modules – up from 5% – covering over 4,100 files across three repositories," said a Meta engineering lead involved in the project.
In preliminary tests, the system achieved 40% fewer AI agent tool calls per task, meaning agents waste less time guessing and exploring. The knowledge layer is model-agnostic, working with most leading models.
Background: AI Without a Map
Meta's data pipeline is config-as-code, spanning four repositories, three languages (Python, C++, Hack), and over 4,100 files. A single data field onboarding touches six subsystems that must stay in sync.
Earlier AI-powered systems handled operational tasks like scanning dashboards, but failed at development tasks. "The AI had no map. It didn't know that two configuration modes use different field names for the same operation – swapping them produces silent wrong output," explained a systems architect.
Without this context, agents would guess, explore, guess again, and often produce code that compiled but was subtly incorrect.
Approach: Pre-Compute Engine with Specialized Agents
Meta built a pre-compute engine using a large-context-window model and task orchestration. The process ran in a single session with over 50 specialized tasks:
- Two explorer agents mapped the codebase
- 11 module analysts read every file and answered five key questions
- Two writers generated 59 context files
- 10+ critic passes ran three rounds of independent quality review
- Four fixers applied corrections
- Eight upgraders refined the routing layer
- Three prompt testers validated 55+ queries across five personas
- Four gap-fillers covered remaining directories
- Three final critics ran integration tests
The system also documented 50+ "non-obvious patterns" – underlying design choices and relationships not immediately apparent from code, such as deprecated enum values that must never be removed due to serialization dependencies.
Self-Maintaining Knowledge Layer
The system maintains itself. Every few weeks, automated jobs validate file paths, detect coverage gaps, re-run quality critics, and auto-fix stale references. "The AI isn’t a consumer of this infrastructure – it’s the engine that runs it," the engineering lead noted.
What This Means
This approach tackles a fundamental challenge for AI coding assistants: understanding the hidden context, or 'tribal knowledge,' that engineers carry in their heads. By pre-computing context files, Meta has created a persistent, model-agnostic knowledge layer that significantly reduces agent errors.
The 40% reduction in tool calls suggests substantial savings in compute costs and latency. Moreover, the system's ability to self-maintain means it can scale to even larger codebases without manual intervention.
Industry observers see this as a template for other large-scale software organizations. "Meta's swarming approach is a pragmatic solution to the AI context problem – it's like giving agents a GPS instead of a compass," commented an AI researcher at a competing firm.
Meta plans to extend the pre-compute engine to more pipelines and share internal best practices widely. The company is also exploring open-sourcing components of the knowledge layer to accelerate industry adoption.